
Labelbox
Founded Year
2018Stage
Series D | AliveTotal Raised
$188.9MValuation
$0000Last Raised
$110M | 3 yrs agoMosaic Score The Mosaic Score is an algorithm that measures the overall financial health and market potential of private companies.
-42 points in the past 30 days
About Labelbox
Labelbox develops a training data platform for machine learning teams to build real-world artificial intelligence (AI) solutions. The platform consists of label editor tools for batch, and real-time labeling workflows, collaboration, quality review, analytics, and more. It serves the government, retail, insurance, manufacturing, and healthcare sectors. It was founded in 2018 and is located in San Francisco, California.
Loading...
Labelbox's Product Videos

ESPs containing Labelbox
The ESP matrix leverages data and analyst insight to identify and rank leading companies in a given technology landscape.
The data annotation market provides services for labeling large volumes of data in preparation for training AI and ML models. This market comprises both text and image & video annotation services. Most companies employ human annotators to classify and label datasets, with some offering AI-powered automation tools to speed up the process.
Labelbox named as Leader among 15 other companies, including Intel, Baidu, and Scale.
Labelbox's Products & Differentiators
Training Data Platform
An end-to-end solution that allows you to search, analyze, annotate and optimize your all in a single place.
Loading...
Research containing Labelbox
Get data-driven expert analysis from the CB Insights Intelligence Unit.
CB Insights Intelligence Analysts have mentioned Labelbox in 8 CB Insights research briefs, most recently on Feb 20, 2024.
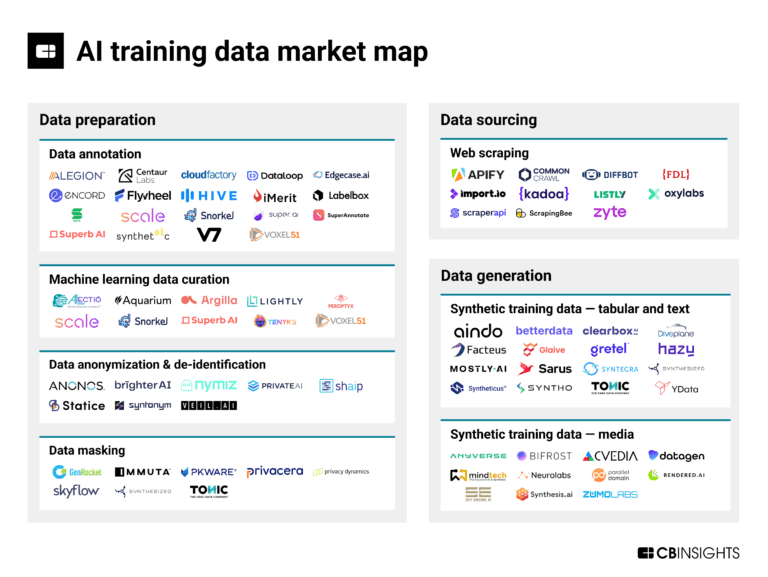
Feb 20, 2024
The AI training data market map

Sep 29, 2023
The machine learning operations (MLOps) market map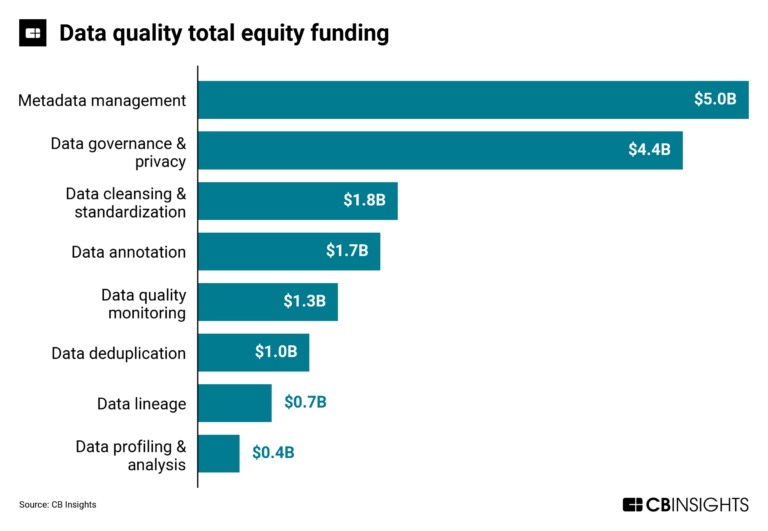
Jul 31, 2023
The data quality market map
Expert Collections containing Labelbox
Expert Collections are analyst-curated lists that highlight the companies you need to know in the most important technology spaces.
Labelbox is included in 1 Expert Collection, including Artificial Intelligence.
Artificial Intelligence
14,767 items
Companies developing artificial intelligence solutions, including cross-industry applications, industry-specific products, and AI infrastructure solutions.
Labelbox Patents
Labelbox has filed 4 patents.
The 3 most popular patent topics include:
- google services
- artificial intelligence
- artificial neural networks
Application Date | Grant Date | Title | Related Topics | Status |
|---|---|---|---|---|
2/3/2022 | 7/18/2023 | Google services, Web applications, Cloud applications, Content management systems, Social networking services | Grant |
Application Date | 2/3/2022 |
|---|---|
Grant Date | 7/18/2023 |
Title | |
Related Topics | Google services, Web applications, Cloud applications, Content management systems, Social networking services |
Status | Grant |
Latest Labelbox News
Sep 6, 2024
by Indium September 6th, 2024 Too Long; Didn't Read Explore how data annotation is crucial to generative AI success. Learn about tools, strategies, & best practices that enhance AI model performance, scalability. Generative AI is reshaping various industries, driving advancements in content creation, healthcare, autonomous systems, and beyond. Data annotation, often overlooked, is the linchpin. Understanding the tools, technologies, and methodologies behind data annotation is crucial to unlocking the full potential of generative AI and addressing the ethical, operational, and strategic challenges it presents. The Imperative of High-Quality Data Annotation Data annotation involves labeling data to make it comprehensible for machine learning models. In generative AI, where the models learn to generate new content, the quality, accuracy, and consistency of annotations directly influence model performance. Unlike traditional AI models, generative AI requires extensive labeled data across a wide spectrum of scenarios, making the annotation process both crucial and complex. 1. The Complexity of Annotation for Generative AI Generative AI models, particularly like Generative Pre-trained Transformers (GPT), are trained on vast datasets comprising unstructured and semi-structured data, including text, images, audio, and video. Each data type requires distinct annotation strategies: Text Annotation: Involves tagging entities, sentiments, contextual meanings, and relationships between entities. This allows the model to generate coherent and contextually appropriate text. Tools like Labelbox and Prodigy are commonly used for text annotation. Image Annotation: Requires tasks such as polygonal segmentation, object detection, and keypoint annotation. Tools like VGG Image Annotator (VIA), SuperAnnotate, and CVAT (Computer Vision Annotation Tool) are used to annotate images for computer vision models. Audio Annotation: Involves transcribing audio, identifying speakers, and labeling acoustic events. Tools like Audacity, Praat, and Voice sauce are used to annotate audio data. Example Code: Image Annotation with CVAT Here’s a sample Python script using CVAT for image annotation. The script demonstrates how to upload images to CVAT, create a new annotation project, and download the annotated data. import cvat_sdkfrom cvat_sdk.api_client import ApiClient, Configurationfrom cvat_sdk.models import CreateTaskRequest, FrameRangeRequest# Initialize the CVAT API clientconfig = Configuration( host=”http://your-cvat-server.com/api/v1″)client = ApiClient(config)auth_token = “your_token_here”# Authenticateclient.set_default_header(“Authorization”, f”Token {auth_token}”)# Create a new task for image annotationtask_request = CreateTaskRequest( name=”Image Annotation Task”, labels=[{“name”: “Object”, “color”: “#FF5733”}])task = client.tasks_api.create(task_request)# Upload images to the taskimage_files = [“image1.jpg”, “image2.jpg”]client.tasks_api.upload_files(task.id, files=image_files)# Start annotatingclient.tasks_api.start_annotation(task.id)# After annotation, download the annotated dataannotations = client.tasks_api.retrieve_annotations(task.id)with open(‘annotations.json’, ‘w’) as f: f.write(annotations.json()) This script leverages CVAT’s Python SDK to streamline the annotation process, making it easier for teams to manage large-scale image annotation projects. 2. The Human-in-the-Loop Paradigm Despite advances in automated labeling, human expertise remains indispensable in the data annotation process, especially in complex scenarios where contextual understanding is crucial. This human-in-the-loop approach enhances annotation accuracy and enables continuous feedback and refinement, ensuring that generative models evolve in alignment with desired outcomes. Investing in high-quality human annotators and establishing rigorous annotation protocols is a strategic decision. Tools like Diffgram offer platforms where human and machine collaboration can be optimized for better annotation outcomes. Tools and Technologies in Data Annotation 1. Annotation Tools and Platforms Various tools and platforms are designed to enhance the efficiency and accuracy of data annotation: Labelbox: A versatile platform that supports annotation for text, image, video, and audio data. It integrates machine learning to assist annotators and provides extensive quality control features. SuperAnnotate: Specializes in image and video annotation with advanced features like auto-segmentation and a collaborative environment for large teams. Prodigy: An annotation tool focused on NLP tasks, offering active learning capabilities to streamline the annotation of large text datasets. Scale AI: Provides a managed service for annotation, combining human expertise with automation to ensure high-quality labeled data for AI models. 2. Automation and AI-Assisted Annotation Automation in data annotation has been greatly advanced by AI-assisted tools. These tools leverage machine learning models to provide initial annotations, which human annotators then refine. This not only speeds up the annotation process but also helps in handling large datasets efficiently. Snorkel: A tool that enables the creation of training datasets by writing labeling functions, allowing for programmatic data labeling. This can be particularly useful in semi-supervised learning environments. Active Learning: An approach where the model identifies the most informative data points that need annotation. 3. Quality Assurance and Auditing Ensuring the quality of annotated data is critical. Tools like Amazon SageMaker Ground Truth provide built-in quality management features, allowing teams to perform quality audits and consistency checks. Additionally, Dataloop offers features like consensus scoring, where multiple annotators work on the same data, and discrepancies are resolved to maintain high annotation quality. 4. Data Management and Integration Efficient data management and integration with existing workflows are vital for the smooth operation of large-scale annotation projects. Platforms like AWS S3 and Google Cloud Storage are often used to store and manage large datasets, while tools like Airflow can automate data pipelines, ensuring that annotated data flows seamlessly into model training processes. The Strategic Value of Data Annotation in Generative AI 1. Enhancing Model Performance The performance of generative AI models is intricately tied to the quality of annotated data. High-quality annotations enable models to learn more effectively, resulting in outputs that are not only accurate but also innovative and valuable. For instance, in NLP, precise entity recognition and contextual tagging enhance the model’s ability to generate contextually appropriate content. 2. Facilitating Scalability As AI initiatives scale, the demand for annotated data grows. Managing this growth efficiently is crucial for sustaining momentum in generative AI projects. Tools like SuperAnnotate and VIA allow organizations to scale their annotation efforts while maintaining consistency and accuracy across diverse data types. 3. Addressing Ethical and Bias Concerns Bias in AI systems often originates from biased training data, leading to skewed outputs. Organizations can mitigate these risks by implementing rigorous quality control in the annotation process and leveraging diverse annotator pools. Adopting tools like Snorkel for programmatic labeling and Amazon SageMaker Clarify for bias detection helps in building more ethical and unbiased generative AI models. Operationalizing Data Annotation: Best Practices 1. Building a Robust Annotation Pipeline Creating a robust data annotation pipeline is essential for the success of generative AI projects. Key components include: Data Collection: Gathering diverse datasets representing various scenarios. Pre-Annotation: Utilizing automated tools for initial labeling. Annotation Guidelines: Developing clear, comprehensive guidelines. Quality Control: Implementing multi-level quality checks. Feedback Loops: Continuously refining annotations based on model performance. 2. Leveraging Advanced Annotation Tools Advanced tools like Prodigy and SuperAnnotate enhance the annotation process by providing AI-assisted features and collaboration platforms. Domain-specific tools, such as those used in autonomous driving, offer specialized capabilities like 3D annotation, crucial for training models in complex environments. 3. Investing in Annotator Training and Retention Investing in the training and retention of human annotators is vital. Ongoing education and career development opportunities, such as certification programs, help maintain high-quality annotation processes and ensure continuity in generative AI projects. Future Trends in Data Annotation for Generative AI 1. Semi-Supervised and Unsupervised Annotation Techniques With the rise of semi-supervised and unsupervised learning techniques, the reliance on large volumes of annotated data is decreasing. However, these methods still require high-quality seed annotations to be effective. Tools like Snorkel are paving the way in this area. 2. The Rise of Synthetic Data Synthetic data generation is emerging as a solution to data scarcity and privacy concerns. Generative models create synthetic datasets, reducing the dependency on real-world annotated data. However, the accuracy of synthetic data relies on the quality of the initial annotations used to train the generative models. 3. Integration with Active Learning Active learning is becoming integral to optimizing annotation resources. By focusing on annotating the most informative data points, active learning reduces the overall data labeling burden, ensuring that models are trained on the most valuable data. 4. Ethical AI and Explainability As demand for explainable AI models grows, the role of data annotation becomes even more critical. Annotations that include explanations for label choices contribute to the development of interpretable models, helping organizations meet regulatory requirements and build trust with users. Conclusion Data annotation is more than just a preliminary step for generative AI . It's the cornerstone that determines these systems' capabilities, performance, and ethical integrity. Investing in high-quality data annotation is crucial for maximizing the potential of generative AI. Organizations prioritizing data annotation will be better equipped to innovate, scale, and stay ahead in the competitive AI landscape. L O A D I N G . . . comments & more!
Labelbox Frequently Asked Questions (FAQ)
When was Labelbox founded?
Labelbox was founded in 2018.
Where is Labelbox's headquarters?
Labelbox's headquarters is located at 510 Treat Avenue, San Francisco.
What is Labelbox's latest funding round?
Labelbox's latest funding round is Series D.
How much did Labelbox raise?
Labelbox raised a total of $188.9M.
Who are the investors of Labelbox?
Investors of Labelbox include Andreessen Horowitz, B Capital, Catherine Wood, SnowPoint Ventures, SoftBank and 9 more.
Who are Labelbox's competitors?
Competitors of Labelbox include Kognic, Superb AI, Scale, Snorkel AI, DataShapes and 7 more.
What products does Labelbox offer?
Labelbox's products include Training Data Platform and 4 more.
Who are Labelbox's customers?
Customers of Labelbox include Genentech, NASA / Jet Propulsion Laboratory, CAPE Analytics and Newmetrix.
Loading...
Compare Labelbox to Competitors

CloudFactory focuses on providing workforce solutions for machine learning and business process optimization. The company offers services such as data labeling, accelerated annotation, and human-in-the-loop automation, which support workflows and fill gaps in artificial intelligence (AI) and automation. CloudFactory primarily serves sectors such as the autonomous vehicles industry, finance, healthcare, insurance, and retail. It was founded in 2010 and is based in Reading, United Kingdom.

Defined.ai provides a range of pre-collected and structured training datasets, including text, voice, and image data, and hosts an online marketplace where these datasets can be bought, sold, or commissioned. Defined.ai caters to the AI development sector, providing data that aids in the creation of fair, accessible, and ethical AI solutions. The company was founded in 2015 and is based in Seattle, Washington.

Sama specializes in providing high-accuracy data annotation solutions for the development of computer vision AI models across various industries. The company offers a suite of services including image and video annotation, 3D point cloud labeling, and data validation to support machine learning professionals and AI team leads. Sama primarily serves sectors such as ADAS & autonomous vehicles, retail & e-commerce, consumer tech & media, robotics & manufacturing, and agriculture & food. It was founded in 2008 and is based in San Francisco, California.

Snorkel AI specializes in data-centric artificial intelligence solutions for the enterprise domain. The company offers an AI data development platform that enables development of AI applications by programmatically labeling and curating data, fine-tuning large language models, and building specialized AI models. It primarily serves sectors such as banking, healthcare, government, insurance, and telecom with its AI technology. The company was founded in 2019 and is based in Redwood City, California.

24x7offshoring specializes in data collection, data annotation, and localization services for various industries. The company offers a platform for artificial intelligence (AI) and machine learning data collection, data labeling, and outsourced services, as well as iterative AI training models. It caters to sectors such as science, technology, education, medical research, and public service. The company was founded in 2020 and is based in New Delhi, India.

SuperAnnotate focuses on artificial intelligence and data management. The company offers a platform for building, iterating, and managing AI models using training data. It provides advanced annotation and quality assurance tools, data curation, automation features, and data governance. SuperAnnotate primarily serves sectors such as agriculture, healthcare, insurance, sports, autonomous driving, robotics, aerial imagery, natural language processing, and security and surveillance. It was founded in 2018 and is based in San Mateo, California.
Loading...