We are running out of high-quality data to train LLMs, driving up demand for synthetic datasets. We dig into how adoption is picking up and the rising players in the space.
Large language models (LLMs) depend on massive quantities of training data, but researchers estimate they’ll exhaust high-quality internet text by 2026.
Outside of costly content licensing deals, model developers and enterprises are turning to synthetic data — artificially generated datasets such as text and images — to supplement AI model training, especially in domains where data availability is limited or privacy is a concern.
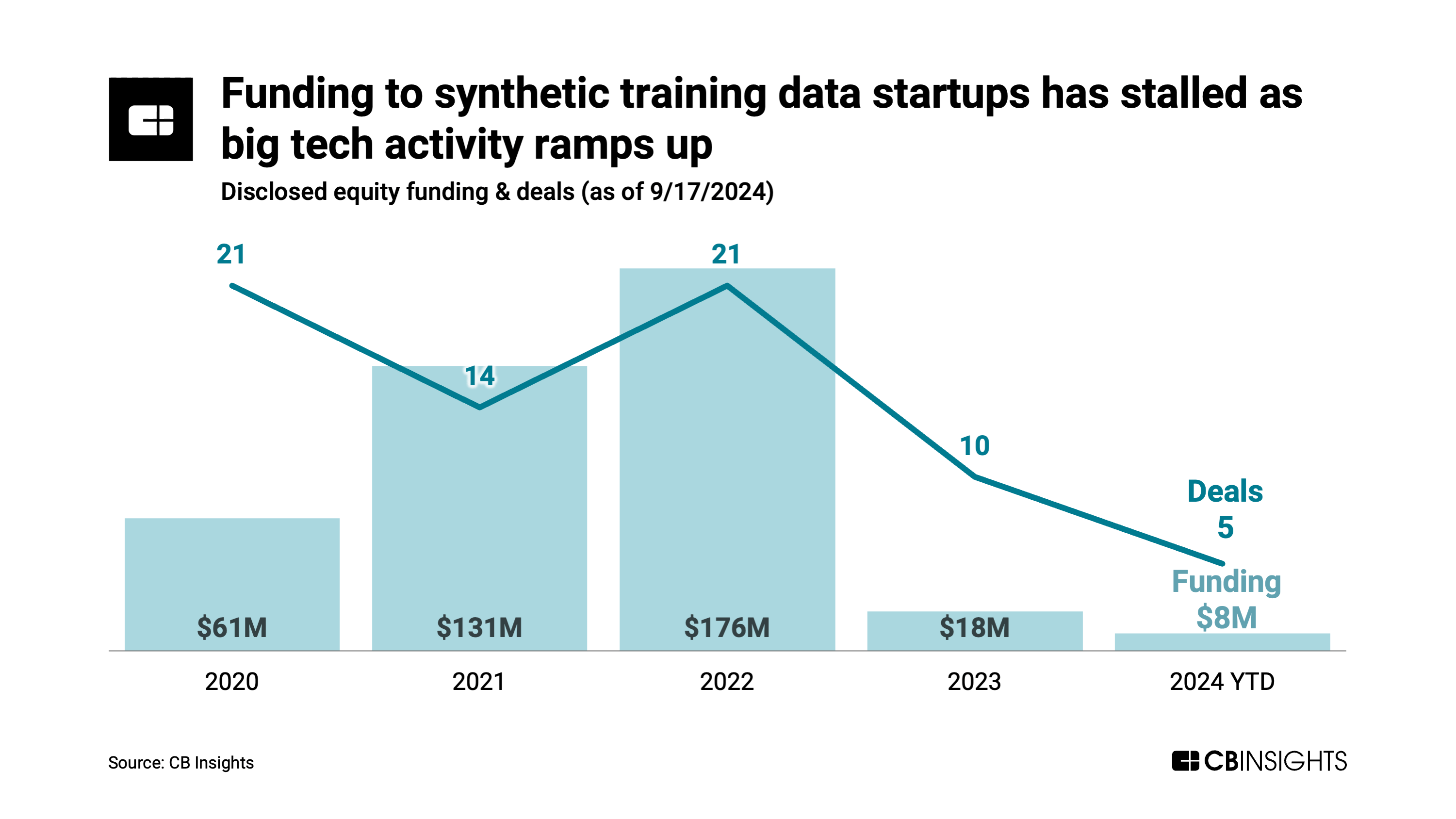
Since 2022, nearly 30 of 50 vendors identified in the synthetic training data space have raised equity funding. But overall funding has stalled as big tech eyes opportunities in the space — and as generative AI itself has upended the business models of data simulation companies founded prior to LLMs mainstream arrival.
Track data on the Synthetic training data — media and Synthetic training data — tabular & text markets.
We examine below emerging opportunities and enterprise adoption of these datasets using CB Insights data, including buyer interviews, funding, headcount trends, and more.
Want to see more research? Join a demo of the CB Insights platform.
If you’re already a customer, log in here.
